Lift & Shift, Zero Downtime, Engineered for Rollback.
When the business needs to move data – not redesign it – we run zero-downtime migrations with cutover patterns and rollback paths engineered before day one.
When Lift & Shift Is the Right Call
Replatforming and refactoring are great when the application architecture is on the table. When it is not – and the business simply needs to get out of a datacentre, retire a licence, or move to a strategic cloud – lift & shift is faster, safer, and lets the redesign work happen on its own timeline.

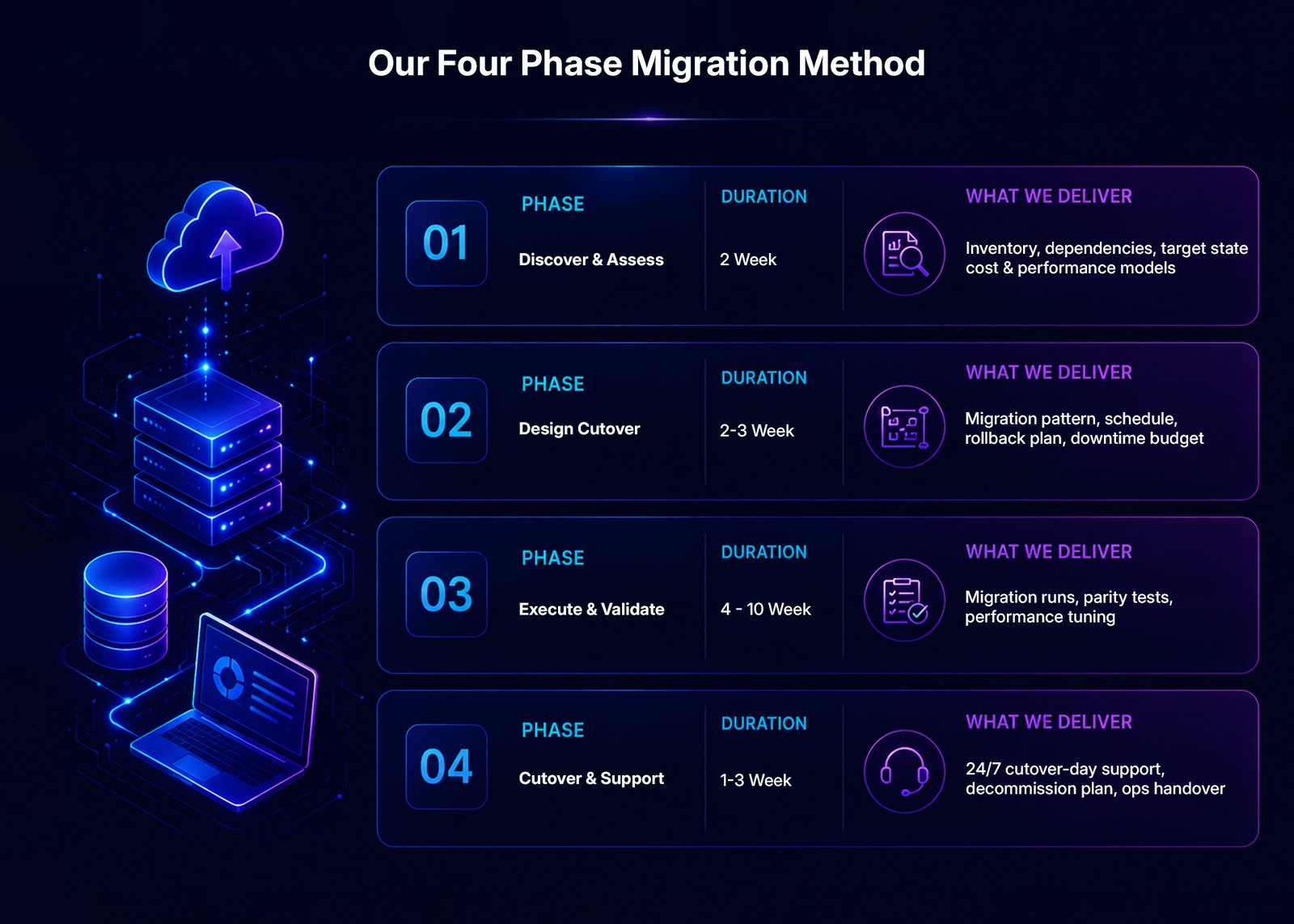
Migrations We Run
Database
SQL Server → Azure SQL / Managed Instance, Oracle → RDS / Azure DB for Oracle / migration to Postgres, MySQL → Aurora
Teradata / Netezza / Exadata → Snowflake, Databricks, Redshift, BigQuery
Hadoop & big-data
On-prem Cloudera / Hortonworks → S3 / ADLS / GCS, Databricks, EMR
File estates
On-prem NFS / SMB / archive → cloud object storage with lifecycle policies
Streaming
Kafka on-prem → MSK / Event Hubs / Confluent Cloud
Baselines benchmarked against incumbent vendor quotes for equivalent scope, with independent advisory validation on engagements over $5M. Total programme TCO includes build, dual-running, training, change management, and 24 month run rate operations full methodology available on request.

Rollback - Always Engineered In
Cutover is not approved until the rollback plan has been tested in staging. We rehearse rollbacks the same way we rehearse cutovers. If we have to use it, it works.
Will Claude write broken code at scale?” is the right question. Our answer is a four-layer correctness model not human review alone.

- Row counts match within tolerance per table.
- Aggregate query results match within numeric tolerance.
- Performance: median and p99 latency within agreed thresholds.
- Application smoke and regression tests pass against the new endpoint.
- Backup, restore, and DR runbooks verified in the new environment.
Human review is the final layer not the only one. The result: AI-suggested code carries the same provenance, attestation, and quality bar as code written by hand.
Every modernization project lives or dies at the cutover. We engineer for safety from day one.
Big-bang (low usage windows).
Where source can be paused. Lowest engineering complexity.
Dual-write
Application writes to both source and target during cutover. Best for OLTP.
CDC + replay
Change-data-capture stream keeps target up to date until traffic flips.
Read-then-write split
Read traffic moves first, write traffic last. Lowest blast radius.

Manufacturing
MES, ERP-adjacent data, plant historians
BFSI
Core-banking adjacent estates, regulatory reporting, AML
Healthcare
EMR adjacent stores, claims, clinical research
Retail
Transaction stores, customer master, supply-chain stores
Supply Chain
WMS / TMS adjacent stores, planning datasets
FAQ
Frequently Asked Questions
Can you migrate while the application keeps running?
For most database and warehouse workloads, yes. The right pattern (dual-write, CDC, or read-first) depends on the application’s tolerance for write latency. We pick after we see the workload.
What about historic data sizes - TB or PB?
We have moved estates from a few hundred GB to several PB. Beyond a few hundred TB, bulk-seed strategies (Snowball / Data Box / physical transfer) usually beat network seeding.
How do you handle licence reductions on the legacy side?
We sequence decommission so legacy can be turned down in stages, freeing licence cost at each milestone. CFO usually sees the saving inside the migration window, not after.
Ready to Move?
Book a 45-minute migration planning call. We will walk through your source estate, recommend a cutover pattern, and put a 90-day delivery plan with rollback rehearsals on the table.