Modernize Legacy Estates 50% Faster With Claude in the Loop.
Why Legacy Slows Everything
Legacy applications were not designed for the speed at which the business now needs to move. They block cloud migration, they hold security debt, and every new release costs more than the last. Replacing them is hard but staying on them is harder.
We modernize legacy estates with AI-led teams: Claude reads, analyses, refactors, and writes test suites at speeds that human-only teams cannot match. Your application stops being a tax on the roadmap and starts being a platform you can build on.

Our Four-Stage Modernization Method
Assessment & ROI
What You Get : Codebase review, dependency mapping, modernization roadmap, ROI analysis
Architect & Pilot
What You Get : Target architecture, reference module rebuilt and deployed
Production Rebuild
What You Get : Module-by-module refactor with parallel run and dual-write where needed
Cutover & Decommission
What You Get : Rolling cutover, legacy decommission, run-book handover
What We Modernize
Mainframe & Midrange
COBOL, RPG, PL/I to cloud-native Java, Python, or .NET.
Refactor into modular monoliths or microservices on AWS, Azure, or GCP.
Aging Frameworks
Struts, JSF, Silverlight, WebForms migrated to React, Angular, or modern Spring Boot
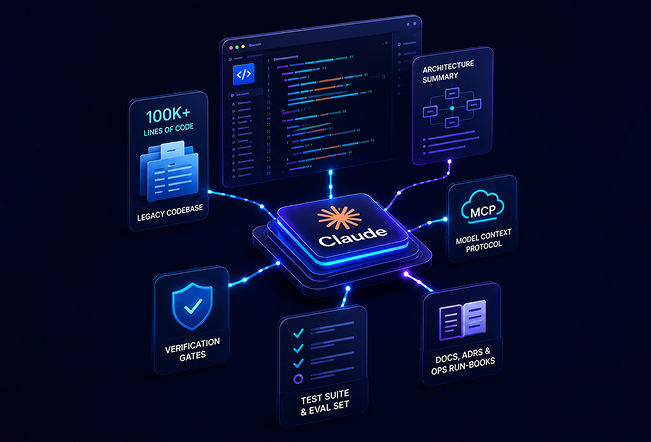
How Claude Accelerates Every Stage
- Reads 100K+ lines of legacy code and produces an architecture grade summary in hours.
- Generates unit and integration tests against legacy behavior before refactor begins test first, not test after.
- Performs multi-file refactors with deterministic verification gates against the test suite and eval set.
- Drafts documentation, ADRs, and ops run-books alongside the code change.
- Integrates with your systems via MCP (Model Context Protocol) for standardized, audited tool access during refactor and validation.
Will Claude write broken code at scale?” is the right question. Our answer is a four-layer correctness model not human review alone.

- Spec-driven inputs. Refactor prompts are built from your architecture docs, ADRs, and style guide not from open ended language.
- Test-first generation. Behavioral tests are generated against the legacy system first, run green, then become the contract the new code must satisfy.
- Deterministic verification gates. Static analysis, type-checks, dependency scans, and the regression suite gate every merge same gate as human-written code.
- Eval-driven CI. A code quality eval suite runs in CI; regressions in correctness, security, or hallucination rate block merge.
Human review is the final layer not the only one. The result: AI-suggested code carries the same provenance, attestation, and quality bar as code written by hand.
Every modernization project lives or dies at the cutover. We engineer for safety from day one.
Engineered Rollback
Cutover plan is not approved until the rollback plan is tested.
Parallel Run
Old and new systems running in shadow with continuous diff checking
Data Parity Validation
Row count, query result, and performance parity verified before sign-off.
Feature Flagged Rollouts
Switch traffic per user, per region, per percentile.

Manufacturing
MES, MRP, ERP integration platform modernisation.
BFSI
core banking, payments, regulatory reporting modernisation.
Healthcare
EMR adapters, claims engines, clinical workflows.
Retail
order management, store-back-office, loyalty.
Supply Chain
TMS, WMS, S&OP platform modernization.
FAQ
Frequently Asked Questions
How is "AI driven digitalisation" different from regular digital transformation?
Traditional transformation projects staff problems with people. We pair AI-native engineers with Claude, Copilot, Cursor, and for repetitive scaffolding work – autonomous coding agents (Claude Code-class), working from structured specs and eval suites rather than ad-hoc prompts. Faster cycles, lower cost, and a path to AI in production, not just AI in pilots.
How do you stop Claude or Copilot from confidently writing broken code?
Four-part answer. (1) Spec-driven inputs: engineers prompt against curated specs – architecture docs, ADRs, style guides – not from memory. (2) Test-first generation: tests written against current behaviour before refactor; the AI must satisfy them. (3) Deterministic verification gates: static analysis, type-checks, dependency scans, and a regression suite gate every merge. (4) Eval suites for code quality: a behavioural eval set runs in CI and blocks merges that regress quality on representative tasks. Human review is the final layer, not the only one.
How is AI-generated code covered for IP and provenance?
We use frontier models via enterprise-tier endpoints with zero-retention configuration and IP indemnity provisions flowed through from our model and tooling vendors (Anthropic, GitHub, Cursor) to our master services agreement with you. Every release ships with SBOM and SLSA-aligned attestation; provenance of AI-suggested code is logged and reviewable. Full IP and data-handling summary on every engagement at MSA stage – not as a separate appendix.
Do you use our codebase to train models?
What about cloud / vendor lock-in?
We deliver to AWS, Azure, and GCP – and we are honest about where each target creates lock-in. Managed services (Aurora, Azure SQL, BigQuery) are platform-coupled by design; we use them when the operational economics justify it and tell you so explicitly. For workloads where portability matters more than per-service convenience, we architect on open foundations (Postgres, Kubernetes, OpenTelemetry) so the exit path is engineered, not improvised.
How do engagements typically start?
Most engagements start with a paid scoping engagement – a structured diagnostic ending in a written assessment, target architecture, and fixed-fee proposal for the build. Pricing is shaped to the scope and outcome, not to a brochure tier. Enterprise and mid-market both supported.