Most Gen AI deployments stall at the pilot. We engineer RAG systems, deploy Copilot at scale, embed dedicated AI teams, and build bespoke Gen AI products that survive the move to production.
The Problem We Solve
Most enterprises are stuck between pilot projects and production-ready AI. Vendors ship demos; nothing ships to users. The reason is rarely the model – it is everything around it: retrieval quality, evaluation, governance, integration, and the cost to run it at scale.
We do the unglamorous work – retrieval design, evals, guardrails, observability, FinOps – so your Gen AI investments actually pay off.

Three practices. One delivery model. Picked and sequenced around the outcome you need first.

Retrieval-Augmented Generation is the workhorse of enterprise Gen AI. We design, build, and operate RAG systems grounded in your documents, tickets, contracts, and code – with source citations, access control, and continuous evaluation.
- Hybrid retrieval (semantic + lexical) tuned to your corpus.
- Chunking strategy and re-ranking calibrated to actual user queries.
- Row-level access control respecting your existing entitlements.
- Eval harness with ground-truth Q&A sets - quality stays measurable in production.
Microsoft 365 Copilot, GitHub Copilot, and custom Copilots that sit inside the tools your teams already use. We handle the rollout, the change management, the security boundary, and the measurement framework so you can prove ROI to finance.
- Readiness assessment: data, identity, licensing, and risk.
- Tenant-level configuration with sensitivity labels and DLP integration.
- Custom Copilot extensions on Power Platform / Copilot Studio.
- Adoption analytics tied to time-saved and quality-of-output metrics.


A dedicated, on-demand AI engineering team – ML engineers, prompt engineers, evaluators, and MLOps – embedded in your sprints. Engaged for 3, 6, or 12-month cycles. Faster to spin up than hiring; cheaper than a Big-Four bench.
- Team profiles built around your roadmap, not a generic catalogue.
- Tier-2 Indian delivery centres with overlapping working hours for US & EU clients.
- Embedded into your tooling - Jira, GitHub, Slack - from day one.
- Knowledge transfer and run-book handover at every milestone.
When the workflow is unique to you, the AI has to be too. Our bespoke practice builds custom Gen AI products – agents, copilots, autonomous workflows – engineered for the way your business actually runs.
- Outcome-based contracts available for scoped builds.
- Agentic workflows with tool use, planning, and human-in-the-loop checkpoints.
- Multi-model strategies (Claude + open-source) chosen per cost and latency budget.
- Production hardening: observability, fallbacks, A/B testing, kill-switches.

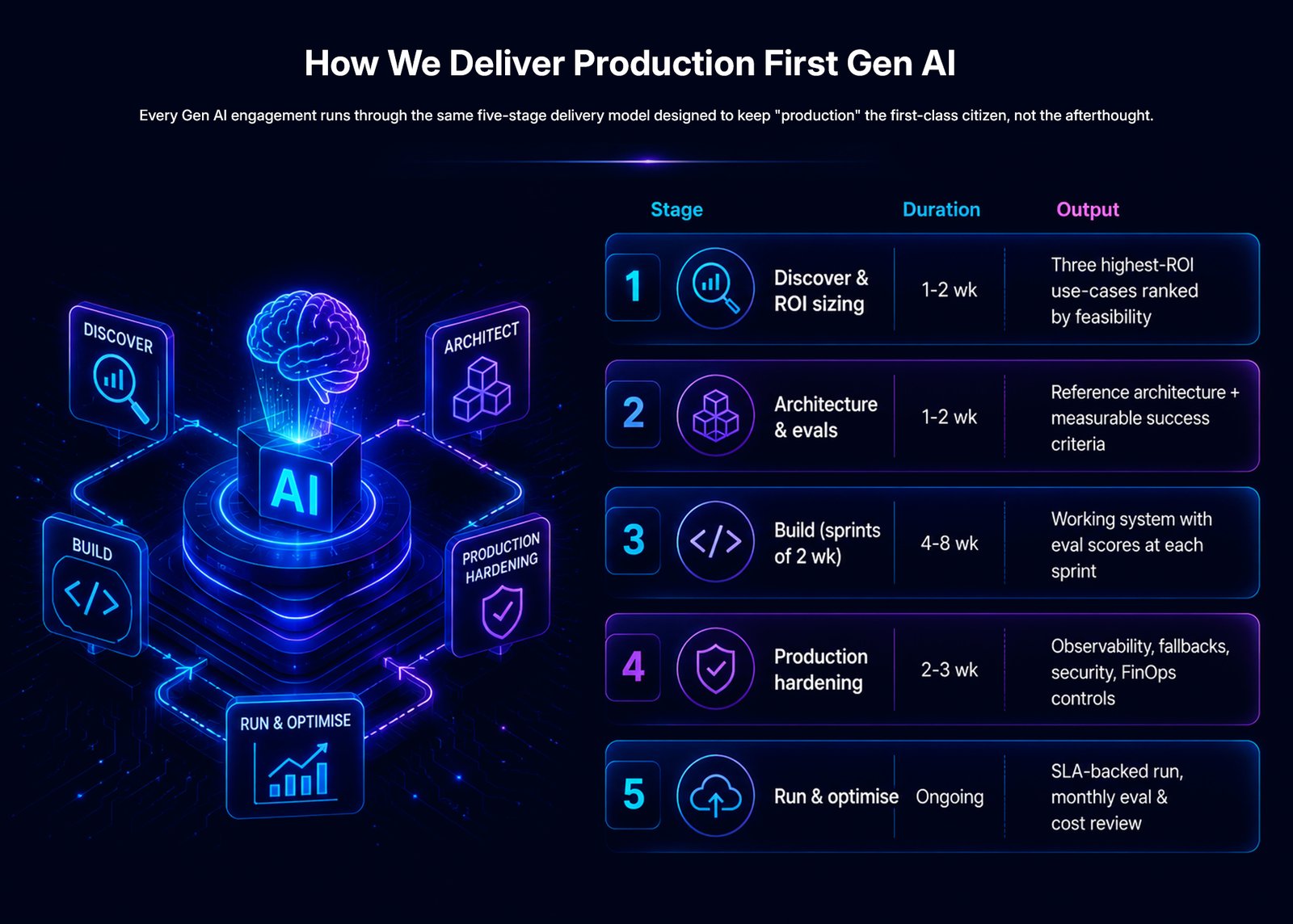
Every Gen AI engagement runs through the same five-stage delivery model – designed to keep “production” the first-class citizen, not the afterthought.
1–2 week
Three highest-ROI use-cases ranked by feasibility, validated against your data availability and team readiness.
1–2 week
Reference architecture tailored to your stack with measurable success criteria defined upfront for every build decision.
4–8 week
Working system delivered in two-week sprints with eval scores at each step and tight stakeholder feedback loops.
2–3 week
Observability, fallbacks, security, and FinOps guardrails layered in with runbooks and dashboards handed to your team.
Ongoing
SLA-backed operations with monthly eval and cost reviews keeping performance sharp as your business scales.
Whether you are assessing your current state or ccelerating an existing roadmap, we bring structure to every stage.
Pay for hit-rate, deflection, or cycle-time targets – measured against pre-agreed evals.
Pod-based Gen AI capacity for exploratory work and roadmap discovery.
Dedicated AI Remote Teams stood up in 4–6 weeks.
Individual prompt engineers, ML engineers, or evaluators on demand.

Anthropic Claude (primary), OpenAI, Google Gemini, plus open-source Llama / Mistral when the cost / latency profile demands it.
LangChain, LlamaIndex, Anthropic SDK, custom in-house orchestrators.
Ragas, Promptfoo, custom golden datasets, LLM-as-judge with calibration against human labels.
Langfuse, Phoenix, Datadog. Per-prompt cost, latency, and quality tracked from day one.
PII redaction, jailbreak detection, output validation, and policy-aware refusal patterns.
Pick the model that fits your budget, risk profile, and roadmap maturity.
Same delivery team
across all four.
You define the KPI; we carry the
execution risk. Ideal for funded
transformation programmed.
engagement for exploratory or
evolving work.
Build-Operate-Manage, Build operate Transfer, or productivity On- Demand pods. Specialist teams stood up in 4 weeks.
FAQ
Frequently Asked Questions
Why does production Gen AI fail so often?
Three reasons, in order of frequency: weak retrieval, no continuous evaluation, and missing observability. Models are the easiest part of the stack to get right; the system around them is where most projects break.
How do you keep our data out of model training?
We use frontier models via private API endpoints with zero-retention configurations. Prompts and responses are never used to train models. Self-hosted open-source options are available for the most sensitive workloads.
Can you guarantee the AI will not hallucinate?
No vendor honestly can. What we do guarantee is a measured hallucination rate against your eval set, monitored in production, with fallbacks and disclaimers when confidence drops below threshold. Hallucination is a system-design problem, not a model bug.
How do you price outcome-driven Gen AI engagements?
We agree the metric, the baseline, and the floor / target / stretch tiers up front. Approximately 30% of fee is tied to the metric, 70% is base. Full pricing memo shared on first call.